Posted on 20/03/2017
Conteúdo
- Introdução
- Motivação
- Uma abordagem neural para aprender representações de palavras
- Experimentos
- Referências
Introdução
Universidade de Oxford em conjunto com a DeepMind disponibilizou o material do curso de Deep Natural Language Processing voltado para pessoas "interessadas em linguagem". Eu particularmente gosto muito de linguagem e inteligência artificial, então decidi dar uma olhada no material. Como a melhor forma que conheço de realmente aprender um conteúdo é estudar até conseguir explicá-lo para os outros, fiz essa postagem resumindo o conteúdo cobrado no primeiro projeto do curso, mostrando o que fiz no projeto e aplicando o que aprendi em um contexto diferente (no caso, literatura em língua portuguesa). A primeira parte do curso é sobre como representar texto em uma linguagem matemática que as máquinas consigam entender e é abordada na segunda semana de aula (aulas 2a e 2b).
Motivação
Neste começo de século, avanços computacionais nos permitiram expandir a noção de dados para algo muito mais heterogêneo e não estruturado. Até recentemente, uma base de dados era logo associada com uma planilha ou tabelas numéricas, cujas colunas representam variáveis e as linhas, observações. Agora, já podemos tratar dados muito menos estruturados, como, por exemplo, texto.
O campo de processamento de linguagem natural (NLP) fornece um sistema com o qual podemos sintetizar automaticamente informações contidas em textos como tweets, notícias, artigos, relatórios contábeis, etc. As aplicações dessa área são tão diversas que não cabe aqui detalhá-las, mas para se ter uma noção, alguns exemplos de onde NLP pode ser utilizado são categorização e sumarização de texto, tradução automática e construção de agentes conversadores. Além disso, no que se refere à inteligência artificial, não há dúvidas que entender a linguagem humana é um passo fundamental para construir sistemas verdadeiramente inteligentes.
Resumindo, podemos entender NLP como um campo da ciência que busca dar às máquinas a capacidade de entender texto. Mas como as máquinas tradicionalmente operam com linguagem matemática, para que elas entendam texto nós precisamos antes codificá-lo em alguma representação numérica. Uma forma ingênua de representar texto seria tratar cada palavra do vocabulário como um vetor one-hot. Por exemplo, se nosso texto for "Olá, meu nome é Matheus", nosso vocabulário seria de 5 palavras: [olá; meu; nome; é; matheus]. Nós então categorizamos cada uma delas em um vetor de tamanho 5 e entradas binárias. Por exemplo, a palavra 'meu' ficaria [0, 1, 0, 0, 0] e a palavra 'é' ficaria [0, 0, 0, 1, 0].
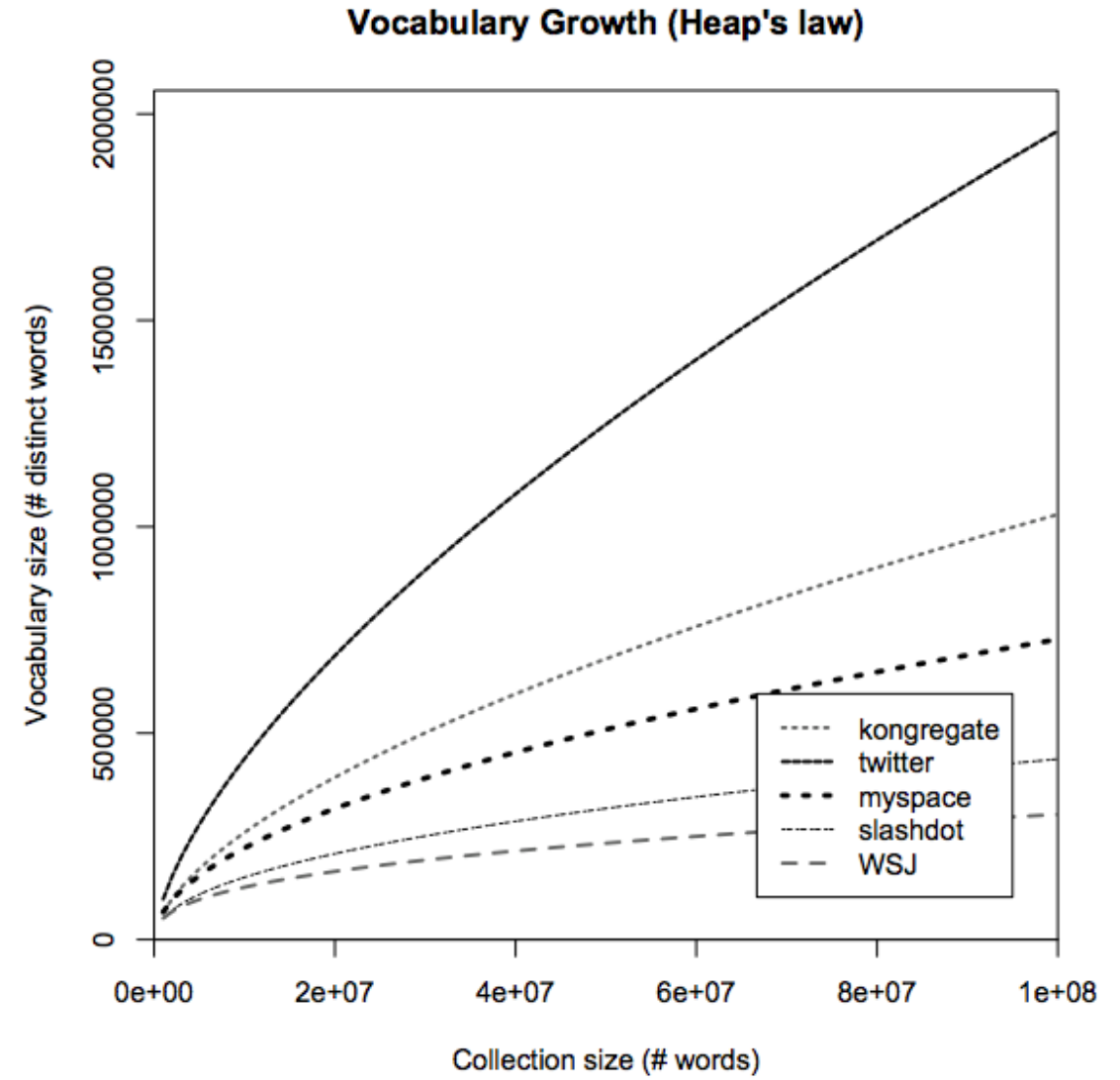
Essa representação tem vários problemas. O primeiro deles é computacional. Os vocabulários reais geralmente são gigantescos e crescem conforme observamos mais texto, pois palavras novas estão sempre surgindo (figura ao lado). Por conta disso cada palavra no texto teria de ser representada como um vetor com centenas de milhares de dimensões, o que demanda muito recurso computacional para processar. Um outro problema é que essa representação ingênua não fornece nenhuma informação sobre a relação entre as palavras. Por exemplo, as palavras 'homem' e 'mulher' carregam várias semelhanças semânticas e sintáticas, mas a representação de vetores one-hot assume que elas são completamente diferentes. Na verdade, essa representação é tão ruim que cada palavra é representada como não tendo semelhança alguma com as outras palavras (em linguagem matemática, podemos dizer que as palavras são representadas por vetores ortogonais). Isso motivou a busca por representações melhores, que tentam diminuir o tamanho (em memória computacional) de cada palavra e ainda incorporar as relações de significado que elas carregam.
Uma abordagem neural para aprender representações de palavras
A forma que trataremos aqui é apenas uma opção de como codificar palavras em representações numéricas, mas saiba que existem outras de eficiência semelhante. A ideia que vamos explorar é a de que "reconhecerás uma palavra pela companhia que ela mantém" (J.R. Firth, 1957), isto é, podemos saber o que uma palavra significa pelo contexto em que ela está inserida. Aqui, vamos ver uma versão de modelo word2vec (Mikolov et al, 2013) chamada Contextual Bag-of-Words (CBoW). Não entrarei em muitos detalhes, pois o modelo demanda conhecimento prévio de redes neurais, mas a intuição dele é bastante simples. Mesmo assim, sugiro ver esta pequena explicação intuitiva sobre o que são redes neurais.
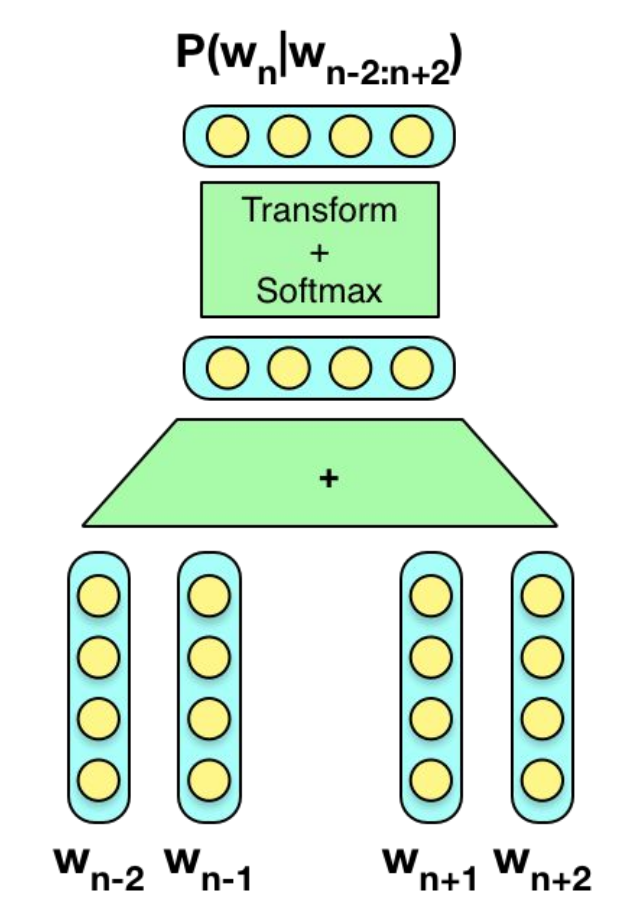
O modelo de CBoW nada mais é do que uma rede neural linear que é treinada para prever uma palavra a partir do contexto em que ela ocorre. Por exemplo, considere a frase "Ele pensava em todas essas coisas quando desejava uma cidade". Nós podemos então definir o contexto da palavra "coisas" como uma janela de palavras em torno dela. Se nossa janela for de 2, por exemplo, o contexto de "coisas" seria ["todas"; "essas"; "quando"; "desejava"]. Nós então utilizaríamos uma rede neural para prever a palavra "coisas" a partir de "todas", "essas", "quando" e "desejava". Por questões de eficiência computacional, nós normalmente definimos outro objetivo: diferenciar a palavra que se encaixa no contexto de palavras aleatórias. Por exemplo, nós alimentamos a rede neural com as palavras do contexto e pedimos que ela diferencie a palavra "coisas" de uma outra palavra aleatória (por exemplo, "xadrez"). Independentemente do objetivo estabelecido, ele deve fazer com que a rede neural precise codificar informações relevantes das palavras nos neurônios da sua camada oculta.
Note que nós não estamos interessados no objetivo definido em si, mas sim na representação interna da primeira camada oculta, que é consequência da otimização do objetivo definido. Essa camada oculta geralmente é da ordem de centenas de neurônios, o que significa que a rede neural tem que condensar a representação one-hot da palavra - um vetor gigantesco, com o número de dimensões do tamanho do vocabulário - em uma camada com algo em torno de 100 dimensões apenas. Esse processo mapeia as palavras de vetores discretos para vetores contínuos. A segunda camada oculta não é muito interessante. Sua função é apenas reformatar as atividades da primeira camada oculta de forma que se possa produzir um valor custo que será minimizado durante o aprendizado.
Se você não está familiarizado com álgebra linear e otimização eu sugiro que ignore o que vou dizer a seguir e pule para a próxima parte. Matematicamente, nós podemos definir a rede neural da seguinte forma:
\[P(\pmb{w}|\pmb{C}) = softmax( (\sum \pmb{c}^T \pmb{E}) \pmb{A})\]Em que estamos interessados em maximizar a probabilidade da palavra \( \pmb{w}\) a partir das palavras de contexto \( \pmb{C}\) (ou diferenciar palavras que encaixam no contexto de palavras aleatórias). A matriz \( \pmb{E}\) representa a primeira camada oculta da rede neural e ela é o que nos interessa mais. Se aprendermos bem os seus parâmetros, nós poderemos utilizá-la para transformar as representações esparsas (one-hot) das palavras em representações densas e que capturarão noções de similaridade semântica e sintática. Agora, note como todas as transformações do modelo são lineares, o que o torna muito simples de treinar.
Experimentos
Treinamos 3 modelos CBoW, dois deles previstos no curso de Deep Natural Language Processing e o último com dados próprios, em português. Cada modelo aprendeu a representar palavras em uma forma numérica, sendo essa representação um vetor de 100 dimensões. Pese nesse vetor como as coordenadas da representação de cada palavra no espaço. Podemos então analisar como essas representações estão dispostas nesse espaço; nossa esperança é que palavras com carga semântica e sintática parecidas estejam próximas umas das outras.
TED Talks
A primeira base de dados que vamos considerar é uma base com HTML de transcrições de 2085 TED talks. A base contém diversas características interessantes, como o tópico da conversa, tempo de cada fala, momento de aplausos; mas para nosso propósito vamos focar apenas no conteúdo da apresentação. Os dados brutos tem a seguinte forma:

Nós vamos processá-los para manter apenas a fala dos palestrantes. Em seguida, vamos separar o texto por frase, o que nos dá um total de 266694 frases. Por fim, vamos converter todas as letras para caixa baixa, separar as frases por palavras e remover qualquer caractere que não for alfabético. Os dados finais tem o seguinte formato:
['here', 'are', 'two', 'reasons', 'companies', 'fail', 'they', 'only', 'do', 'more', 'of', 'the', 'same', 'or', 'they', 'only', 'do', 'what', 's', 'new']
['to', 'me', 'the', 'real', 'real', 'solution', 'to', 'quality', 'growth', 'is', 'figuring', 'out', 'the', 'balance', 'between', 'two', 'activities', 'exploration', 'and', 'exploitation']
Treinamos então um modelo CBoW nos dados e conseguimos as representações de cada palavra. Nossa primeira forma de avaliação das representações aprendidas será ver se a distância entre elas faz sentido, isto é, se pontos que representam palavras similares estão próximos uns dos outros no espaço de representações. Por exemplo, nós gostaríamos que as palavras "homem" e "mulher" estejam mais perto entre si do que "homem" esteja perto da palavra "correr". Na tabela abaixo, estão dispostas 7 palavras e as palavras mais próximas a elas no espaço das representações, em ordem decrescente de proximidade. Pense em cada coluna da tabela como uma lista de vizinhos mais próximos da palavra em negrito.
| technology | entertainment | design | man | woman | dream | marriage |
|---|---|---|---|---|---|---|
| knowledge | engineering | engineering | woman | man | passion | penalty |
| design | tourism | technology | guy | girl | legacy | minister |
| technologies | sciences | biology | lady | lady | faith | torture |
| content | educational | model | girl | boy | career | sport |
| method | enterprise | architecture | boy | child | client | physician |
| tools | cyber | mathematics | gentleman | kid | gift | diagnosis |
| tool | finance | science | david | nurse | son | vice |
| process | crispr | mathematical | poet | guy | profession | battle |
| biology | humanities | tool | kid | parent | daughter | parent |
| digital | promoting | approach | soldier | teacher | husband | survivor |
Como TED é um acrônimo para tecnologia, entretenimento e design, eu achei que seria interessante começar analisando essas palavras. Nós podemos ver como elas aparecem próximas umas da outras, indicando que os palestrantes as utilizam no mesmo contexto. Em seguida, vemos como as palavras "homem" e "mulher" são similares, mas é interessante notar como a primeira é mais similar a cavalheiro, poeta e soldado, enquanto que a última está mais próxima de enfermeira, parente e professora. Se fizermos uma análise mais crítica, podemos até dizer que, por mais progressista que seja o TED, alguns padrões sociais retrógrados ainda aparecem, pelo menos do ponto de vista linguístico. Por fim, achei interessante analisar as palavras "casamento" e "sonho". Note como essa última aparece associada à paixão, legado e carreira enquanto que a primeira aparece mais próxima de penalidade, tortura, vicio e batalha. Não é possível dizer ao certo porque "casamento" é associado a essas palavras negativas. Pode ser que o casamento seja de fato visto dessa forma pelos palestrantes ou pode ser que não haja ocorrências suficientes da palavra "casamento" para aprender bem a sua representação.
Como as palavras são representadas em forma numérica, nós podemos fazer operações matemáticas com elas. Se subtrairmos uma representação da outra, o resultado será um novo ponto no espaço de representações. Esse ponto pode ser interpretado como a diferença semântica entre as palavras consideradas ou como a subtração de uma noção semântica. A soma de representações funciona de forma análoga e pode ser entendida como uma adição de carga semântica a uma palavra. Por exemplo, nós podemos subtrair da representação de "rei" a representação de "homem" e adicionar a representação de "mulher". O resultado então é um ponto que fica próximo da representação da palavra "rainha". Isso nos mostra como nosso modelo foi capaz de aprender analogias de gênero entre palavras, por exemplo a presente entre as frases "ele é o rei" e "ela é a rainha ". A seguir podemos ver três representações formadas pela adição e subtração de representações, seguida dos respectivos vizinhos mais próximos.
| king - man + woman | computer + mind - man | life + meaning |
|---|---|---|
| president | testing | happiness |
| james | memory | experience |
| german | 3d | identity |
| prime | dna | success |
| queen | brain | desire |
| french | biology | creativity |
| mary | biological | purpose |
| obama | physical | behavior |
Podemos ver que as analogias não foram tão bem aprendidas assim, uma vez que a palavra "rainha" é apena a quinta mais próxima da representação formada por \( rei-homem+mulher\) . Mesmo assim, é interessante ver o que o modelo consegue com tais analogias. Por exemplo nós podemos nos perguntar como fica a representação da diferença entre um computador com mente e o homem ou como é a representação da palavra "vida" mais a palavra "sentido". No primeiro caso, vemos as palavras "biologia", "cérebro", "dna", o que faz certo sentido, afinal um computador com mente ainda assim seria diferente do homem por não ter uma composição biológica. No segundo caso, nos vizinhos mais próximos da representação \( vida + sentido\) estão as palavras "felicidade", "sucesso" e "desejo", o que nos mostra (de forma meio vaga) o que os palestrantes do TED entendem por uma vida com sentido.
Por fim, nós podemos visualizar essas representações em um gráfico. Como as representações que aprendemos são pontos em um espaço de 100 dimensões, nós precisamos antes reduzi-las para pontos em duas dimensões, afim de visualizá-las. Para isso, vamos utilizar uma técnica chamada t-Distributed Stochastic Neighbor Embedding ou apenas t-SNE. A vantagem dessa técnica é que ela mantém a noção de vizinhança enquanto evita muita sobreposição dos pontos. No entanto, há bastante aleatoriedade na otimização de t-SNE, então nós devemos interpretar seu resultado com cautela. Além disso, existe uma clara perda de informação ao reduzir 100 dimensões para duas. Sinta-se a vontade para explorar essa gráfico. Basta clicar no ícone da lupa para ativar zoom.
Acima está o gráfico das projeções em 2D das representações das 1000 palavras mais comuns no nosso vocabulário. Nós podemos explorar mais de perto esse gráfico para ver melhor como as palavras se agrupam no espaço de representações. Por exemplo, abaixo podemos notar que as palavras "ele" e "ela" estão extremamente próximas, indicando que elas são utilizadas no mesmo contexto. Na parte de baixo do gráfico, podemos ver como partes do corpo se agrupam e do lado direito vemos um agrupamento de recursos naturais.
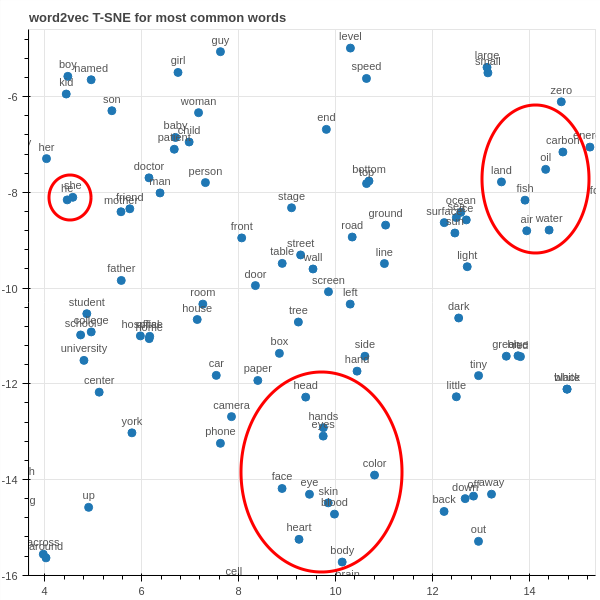
Obs: o gráfico interativo e o estático são de execuções diferentes do t-SNE, então, devido a aleatoriedade no processo, os agrupamentos destacados acima podem não estar presentes no gráfico interativo.
Wikipédia
Nosso segundo experimento foi com os artigos da Wikipédia em inglês. Essa base de dados é bem maior do que a primeira e contém uma quantidade massiva de palavras, contando com 4'267'112 frases. Foram precisos mais de 12 GB de RAM para processar todo esse texto, então recomendo reproduzir esse experimento apenas em computadores com recursos razoáveis de memória. Nós então refizemos o mesmo tipo de análise conduzida acima, começando com a identificação dos vizinhos mais próximos de algumas palavras no espaço de representações.
| man | woman | marriage | love |
|---|---|---|---|
| woman | girl | divorce | dreams |
| person | man | marriages | kiss |
| girl | child | husband | duet |
| boy | prostitute | betrothal | romance |
| soldier | person | marrying | loving |
| dog | lover | wife | madly |
| creature | maid | remarriage | sadness |
| lad | beggar | spouse | infatuation |
Podemos ver que o texto da Wikipédia parece ainda mais sexista do que o das palestras do TED. Por outro lado, a palavra casamento não parece estar mais ligada a uma carga semântica tão negativa. Ainda assim, parece que as palavras casamento e amor estão bem distantes no espaço de representações, pois elas não compartilham nenhum dos 5 vizinhos mais próximos.
Em seguida, podemos ver novamente as analogias formadas pela soma e subtração de representações. Uma analogia particularmente interessante que nosso modelo aprende é a de "país -> capital", como mostrado na última coluna da tabela abaixo. As noções de gênero também parecem mais claras nesse modelo, já que os vizinhos mais próximos da representação \( rei - homem + mulher\) é "imperatriz", "rainha" e "monarca". Por fim, podemos ver que a noção de vida com significado é capturada por um ponto próximo das palavras "realização" e "essência", o que faz pleno sentido.
| king - man + woman | life+meaning | paris - france + japan |
|---|---|---|
| empress | sense | tokyo |
| queen | realization | shibuya |
| monarch | essence | shinjuku |
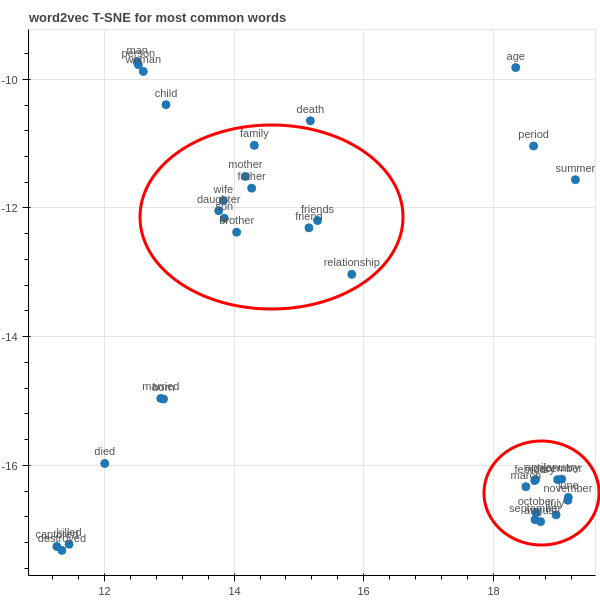
Por fim, podemos visualizar novamente a projeção das representações em um espaço 2D com t-SNE.
Se ampliarmos, podemos ver como os meses se agrupam em um círculo bem interessante. Também podemos ver mais no meio como se agrupam as representações de algumas relações pessoais (novamente, pode haver divergência entre a parte ampliada e o gráfico interativo, devido a aleatoriedade do t-SNE).
Literatura
Por último refizemos o mesmo experimento acima com textos de literatura em português. Como dados, foram utilizados textos de vários livros de prosa; dentre os autores considerados estão Machado de Assis, Saramago, Valter Hugo Mãe, Ítalo Calvino, Borges, James Joyce, Orhan Pamuk, Dumas, Balzac, Mia Couto, Lewis Carroll, Dostoievski, Tolstoi, Virginia Woolf, Cervantes, Umberto Eco, Goethe, H. G. Wells, Herman Hesse, Mikhail Bulgakov, Garcia Marquez, Victor Hugo e William Faulkner. Isso nos deu um total de 296415 frases, o que indica que a base construída tem mais ou menos a mesma dimensão da do TED talks. Novamente, procedemos vendo a relação de proximidade entre as palavras.
| homem | mulher | crime |
|---|---|---|
| animal | moça | pecado |
| rapaz | criança | erro |
| ladrão | menina | castigo |
| individuo | filha | absurdo |
| pintor | rapariga | problema |
Na última coluna, pelos vizinhos mais próximos da palavra "crime" podemos notar que nosso modelo aprendeu bem a relação semântica entre as palavras. Particularmente interessante é o fato da representação da palavra "castigo" aparecer como o terceiro vizinho mais próximo da representação da palavra "crime". Incrivelmente, o texto literário, mesmo contendo vários autores antigos, aparenta ser o menos sexista de todos. Claro que a proximidade de "mulher" com "criança" ainda indica um certo machismo, seja de infantilização da mulher ou de pressuposto de maternidade, mas só fui capaz de detectar isso (a palavra "rapariga" provavelmente não tem sentido negativo se considerarmos a grande quantidade de livros de Saramago incluída na base de dados). Por outro lado, a palavra "homem" aparece agora com um carga semântica muito mais negativa.
A seguir, resolvi observar mais três palavras que tratam de temas frequentemente abordados na literatura.
| sonho | amor | morte |
|---|---|---|
| pensamento | ódio | cegueira |
| delírio | temor | vida |
| ato | sofrimento | doença |
| sono | orgulho | existência |
| casamento | coração | culpa |
É interessante notar como agora a palavra "casamento" aparece próxima de "sonho", sendo esse o único dos 3 experimentos em que casamento parece ter uma conotação positiva. Além disso, repare nos vizinhos mais próximos da palavra "amor". Provavelmente essas relações são reflexo dos textos românticos incluídos na base de dados. Também vale a pena reparar em como a palavra "morte" está próxima de "vida" e "existência".
O próximo passo foi analisar as representações obtidas pela adição e subtração de palavras.
| roma - itália + frança | barco - navegar | homem - deus |
|---|---|---|
| napoleão | quarto | usava |
| julho | jeito | parecia |
| paris | carro | vestia |
| angoulême | cego | amarelo |
| março | comenos | ruído |
Novamente, a analogia de "país -> capital" foi bem capturada pelo modelo, como podemos ver na primeira coluna. As outras duas colunas não tem interpretações tão claras. Quanto a do meio, fiquei satisfeito em ver que "carro" é um dos vizinhos mais próximos do ponto obtido com \( barco - navegar\) , mas não está claro porque "quarto", "cego" ou "comenos" aparecem próximos desse ponto. Na última coluna, queria ver o que os mestres da literatura entendiam pelo significado da palavra "deus" subtraído da palavra "homem", mas os vizinhos mais próximos desse ponto não indicaram nada de interessante. Eu estava esperando vizinhos como "fraco" ou "livre", mas em vez disso observamos as palavras "ruído" e "amarelo".
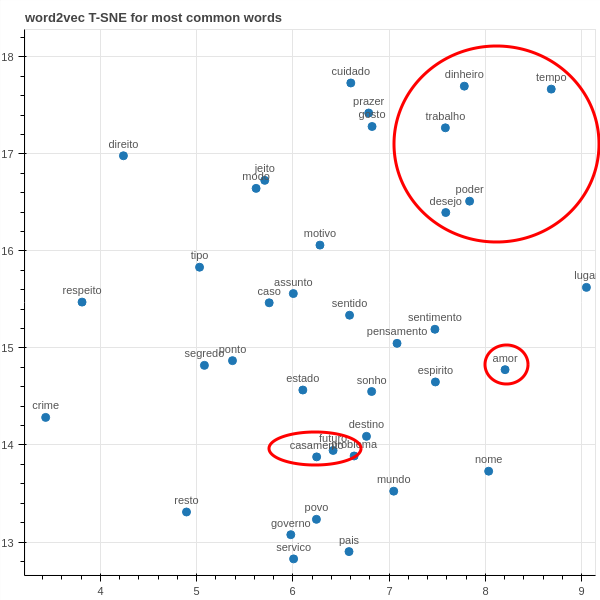
Finalizamos com uma visualização da projeção das representações aprendidas em um espaço 2D com t-SNE.
Quando ampliamos um agrupamento, podemos ver melhor as relações de proximidade das projeções. Para mim, particularmente interessante são as palavras agrupadas no canto superior direito do gráfico abaixo. Além disso, podemos ver que as palavras "amor" e "casamento" finalmente aparecem próximas (novamente, pode haver divergência entre a parte ampliada e o gráfico interativo, devido a aleatoriedade do t-SNE).
Referências
Exceto pelos gráficos, todas as imagens foram obtidas a partir dos slides das aulas de Deep Natural Language Processing. Mais ainda, praticamente toda a referência teórica foi retirada desse curso. Ainda assim, vale citar algumas referências externas sobre aprendizado de representações de palavras:
- colah's blog: Deep Learning, NLP, and Representations;
- A Neural Probabilistic Language Model, por Bengio et al;
- Learning Feature Vectors for Words, vídeos por Geoffrey Hinton
Você pode também pode clonar esse projeto no meu GitHub. O experimento do TED talks é facilmente reproduzível, já que a base de dados é pequena e os dados estão disponíveis para download. O experimento da Wikipédia também pode ser reproduzido sem grandes esforços, supondo que seu computador tenha mais de 12 GB de RAM. Para não tornar o repositório no GitHub muito pesado, eu não disponibilizei os dados de literatura para download, mas, caso queira reproduzir este último experimento, entre em contato que lhe encaminharei os dados.