Posted on 1/06/2017
Conteúdo
Introdução
Vamos analisar gastos de consumidores para entender os padrões e estrutura de consumo. Os dados são de um atacadista que contabilizou gastos de consumidores em seis categorias: frescos (Fresh), leite (Milk), mercearia (Grocery), congelado (Frozen), detergente e papel (Detergents_Paper) e Delicatessen (Delicatessen). O objetivo aqui será entender melhor a estrutura desses gastos, como eles se relacionam e se há algum padrão que pode ser explorado para otimizar as vendas.
Análise Exploratória
Em primeiro lugar, vamos explorar algumas estatísticas simples dos nossos dados, tais como média de gastos por produto, desvio padrão e quantis dos dados.
| Fresh | Milk | Grocery | Frozen | Detergents_Paper | Delicatessen | |
|---|---|---|---|---|---|---|
| Média | 12000.29 | 5796.26 | 7951.27 | 3071.93 | 2881.49 | 1524.87 |
| Desvio Padrão | 12647.33 | 7380.38 | 9503.16 | 4854.67 | 4767.85 | 2820.10 |
| Mín. | 3.00 | 55.00 | 3.00 | 25.00 | 3.00 | 3.00 |
| 25% | 3127.75 | 1533.00 | 2153.00 | 742.25 | 256.75 | 408.25 |
| 50% | 8504.00 | 3627.00 | 4755.50 | 1526.00 | 816.50 | 965.50 |
| 75% | 16933.75 | 7190.25 | 10655.75 | 3554.25 | 3922.00 | 1820.25 |
| Máx. | 112151.00 | 73498.00 | 92780.00 | 60869.00 | 40827.00 | 47943.00 |
Podemos ver que, em média, a maioria dos gastos dos consumidores é com frescos. Em seguida, gasta-se mais com mercearia, leite, congelados, detergente/papel e delicatssen, nessa ordem. Além disso, os gastos com delicatssen são bem menores do que os com outros produtos.
Usando um modelo de previsão linear simples, notei que 70% dos gastos com mercearia (Grocery) pode ser explicado pelos gastos nos outros produtos. Isso torna a variável de mercearia parcialmente redundante nos dados. Se tivéssemos muitas variáveis, por eficiência computacional, seria uma boa retirá-la dos dados. Como só temos 6 variáveis, vamos mantê-la. Em seguida, apliquei o logaritmo natural em todas as variáveis. Isso faz com que a distribuição delas fique melhor comportada, isto é, mais próxima de uma gaussiana (curva de sino). Após essa etapa de processamento, coloquei as distribuições e as correlações das variáveis num gráfico.
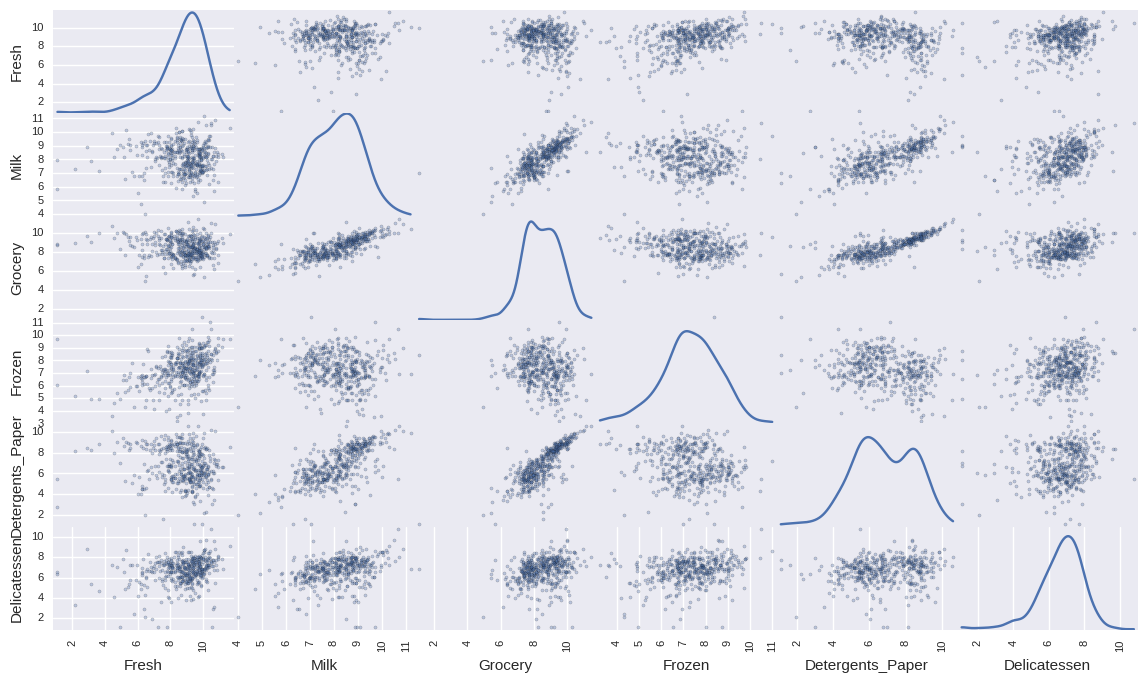
Aparentemente, há uma elevada correlação entre Grocery e Detergents_Paper; há também alguma correlação entre Grocery e Milk e entre Milk e Detergents_Paper. Isso já nos dá alguma informação sobre o comportamento dos consumidores: quando eles compram produtos de mercearia (Grocery), tendem também a comprar produtos nas categorias papel/detergente e leite. Mais ainda, essas correlações confirmam o que havíamos visto antes, sobre gastos com mercearia serem um tanto redundantes.
Análise de Componentes Principais
A análise de componentes principais é um método de extração de características que busca achar os (tãn tãn tãn tãn!!!) componentes principais dos dados. Como um exemplo super simples, digamos que os consumidores do atacado em questão sejam apenas mães ou pais de crianças pequenas. Nos dados, só temos as quantidades gastas desses consumidores, mas podemos imaginar que esses gastos são manifestações de características que não podemos observar, como estilo de vida. O que podemos fazer então é combinar as nossas variáveis observadas (gastos) para criar variáveis explicativas que melhor condensam os padrões de consumo. Por exemplo, se notarmos que gastos com fraldas e leite em pó variam junto, podemos combinar essas duas variáveis em um único componente, que captura certa essência do fator não observável hábito de consumo de uma família com crianças pequenas. Com isso, reduzimos o número de variáveis nos dados, mas mantemos a informação presente neles: em vez de precisarmos acompanhar duas variáveis de gastos, só precisaremos acompanhar a variação desse novo componente criado. Intuitivamente, podemos pensar nesse componente como representando um fator latente de variação nos dados observáveis. Talvez esse fator latente seja estrutura familiar, mas, de qualquer forma o importante é que ele ajude a explicar variações de consumo.
Análise de Componentes Principais (ACP) faz justamente isso. Essa técnica maximiza a variação dos dados nos componentes extraídos, ao mesmo tempo que minimiza o erro de reconstrução, isto é, minimiza a perda de informação que se tem ao manter apenas os componentes principais mais importantes, descartando-se os demais. Usando ACP, substituímos nossas 6 variáveis observáveis em seis componentes principais, sendo que os primeiros componentes explicam a maioria da variação nos dados originais, isto é, no consumo. Podemos inclusive ver como as variáveis originais são utilizadas para criar esses componentes.
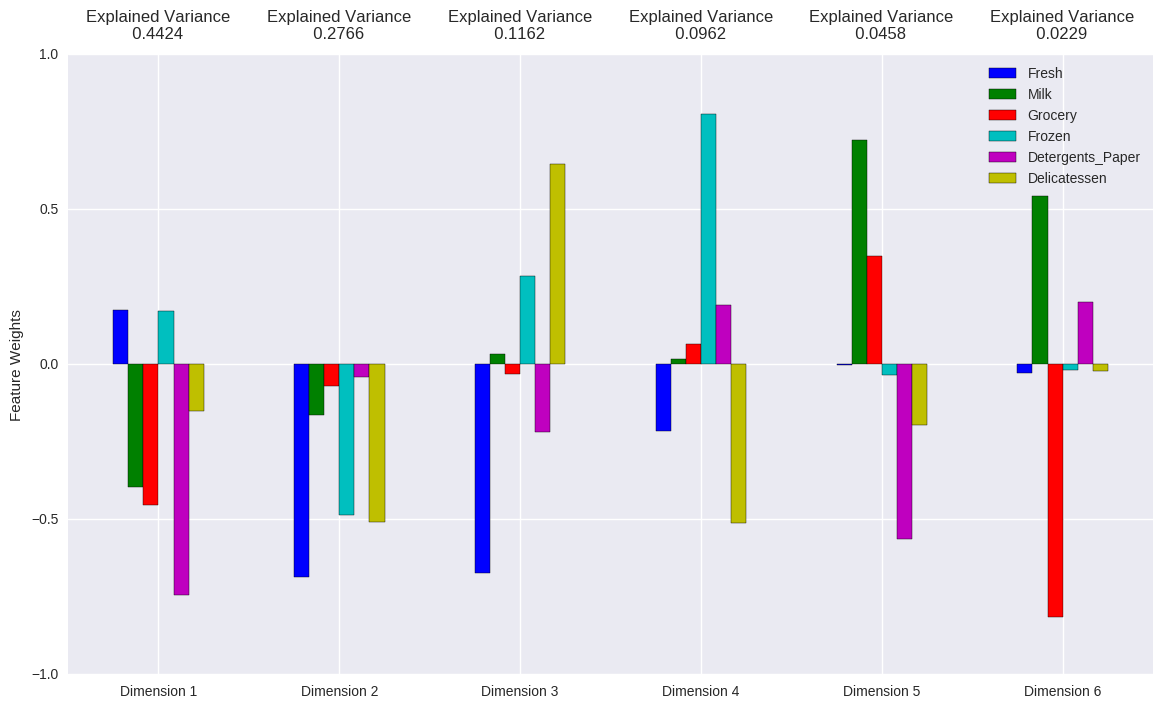
Note como 71,9% (0,4424 + 0,2766) da variação nos dados pode ser explicada pelos dois primeiros componentes principais e como os quatro primeiros explicam 93,14% dessa variância. O primeiro componente principal é composto majoritariamente por Detergent_Paper e um pouco por Milk e Grocery. A partir deste componente principal, podemos ver que os clientes que gastam mais com leite tendem a gastar mais em mercearia e em detergente/papel. Também mostra que os clientes diferem principalmente pela diferença nos gastos com esses três produtos. O segundo componente principal, por sua vez, é composto principalmente por Fresh, Frozen e Delicatssen. Isso mostra que a segunda maior fonte de diferença entre os clientes vem de seus gastos com produtos frescos, congelados e delicatssen. A partir desse componente principal, podemos inferir que os clientes que gastam mais em frescos também tendem a gastar mais em congelados e delicatssen. O mesmo raciocínio pode ser feito para os outros componentes extraídos. Antes de prosseguir, descartei todos os componentes principais menos os dois primeiros. Isso resulta em certa perda de informação, mas nada grave, já que eles sozinhos preservam quase 72% da informação original. Como só estamos com dois componentes principais, podemos colocá-los em um gráfico e visualizar como as variáveis originais de consumo estão relacionadas com os dois primeiros componentes principais.
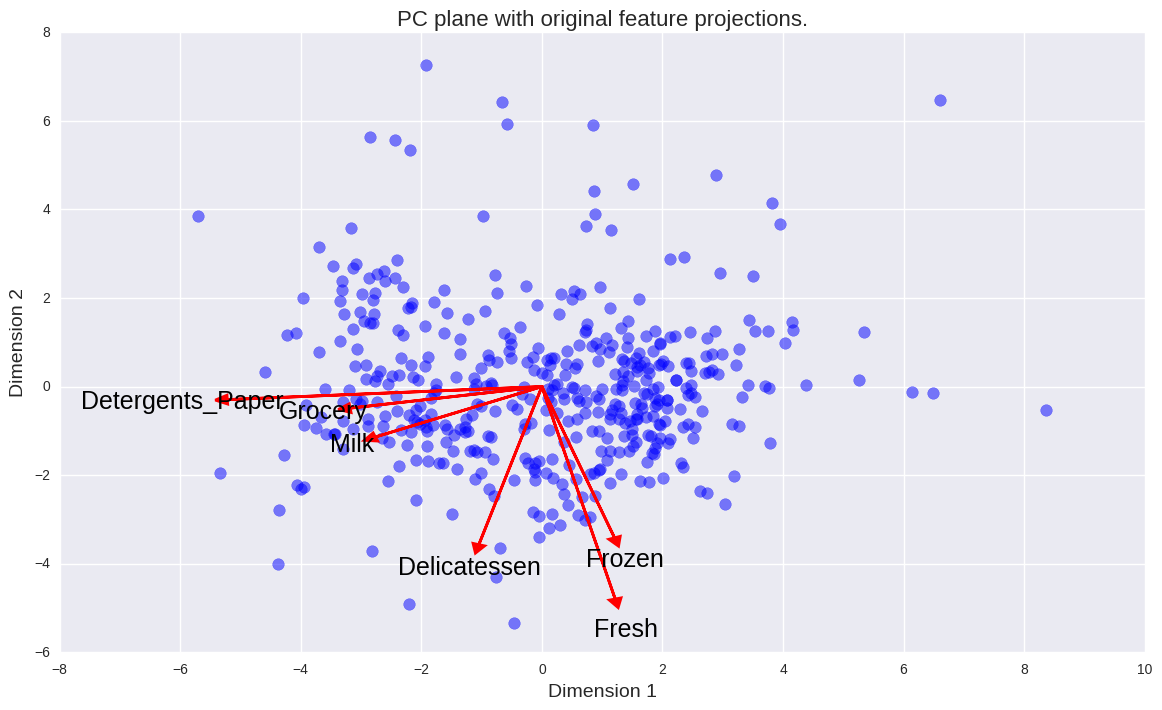
Claramente, quanto mais negativo for o primeiro componente principal de uma observação, mais esse consumidor compra leite, produtos de mercearia e detergente/papel. Além disso, consumidores com o primeiro componente principal positivo compram menos de todas as categorias de produtos, o que me leva a crer que são, provavelmente, estabelecimentos menores. Com o mesmo tipo de raciocínio, podemos dizer que consumidores cujo segundo componente principal é negativo compram mais frescos, congelados e delicatssen.
Clusterização
Com os dados reduzidos, prossegui para algoritmos de clusterização, para tentar identificar segmentos de mercado. O método usado foi de Expectativa-Maximização, que identifica clusters de forma iterativa. O número ótimo de clusters encontrado foi dois.

A próxima parte da análise requer um pouco de adivinhação e intuição, uma vez que não é absolutamente claro o que cada um desses agrupamentos significa. Podemos ver que o segmento representado pelo agrupamento 0 gasta mais que a média com produtos detergentes/papel e mercearia. Isso fica claro por esse segmento estar em uma região negativa do primeiro componente (lembre-se de que o primeiro componente é composto principalmente por detergentes/papel e mercearia, mas de forma inversa ou negativa). Isso me leva a crer que o agrupamento 0 representa estabelecimentos como mercados varejistas, que compram esses produtos provavelmente para revender.
O segmento 1, por outro lado, compra menos que a média em todas as categorias. Isso me leva a acreditar que ele representa estabelecimentos menores, como padarias, cafés ou restaurantes. Esse agrupamento também adquire muitos frescos (perto da média) que reforça minha hipótese de que ele representa algum tipo de estabelecimento que serve comida, como restaurantes.
Se pegamos observações extremas, como o X no canto superior direito, podemos conjecturar que ele é um estabelecimento muito pequeno. Talvez uma pessoa física ou um pequeno café. No outro oposto, o X no canto esquerdo inferior deve ser algum supermercado. Exemplos mais na fronteira entre os clusters são mais ambíguos. Por exemplo, não está claro que tipo de estabelecimento é o X no centro superior.
Após toda essa análise, é importante mostrar como a informação adquirida no processo pode ser útil para o atacado. Em primeiro lugar, tendo conhecimento dos tipos de consumidores, o atacado pode pensar em serviços que atendam melhor alguma das categorias. Um exemplo seria criar um serviço de entrega de produtos com rota especializada para passar em todos os supermercados ou em todos os hotéis ou cafés. Outra possibilidade para aumentar as vendas é organizar os produtos nas prateleiras de forma que os que são comprados conjuntamente fiquem próximos.
Referências
Este trabalho é uma adaptação do terceiro projeto do Nanodegree Engenheiro de Machine Learning da Udacity. Se você está fazendo esse Nanodegree, saiba que uma série de sanções lhe podem ser aplicadas por submeter trabalho que não é seu. Assim, eu recomendo fortemente tente antes a sua própria implementação antes de olhar a minha.
Você pode conferir a implementação completa do projeto (em inglês) no meu GitHub.