Posted on 15/03/2017
Pré-requisitos
Vou pressupor que você tenha os conhecimentos especificados no tutorial sobre matemática e programação para aprendizado de máquina, isto é, que sabe cálculo (derivadas), o básico de álgebra linear, de estatística e de programação. Eu também vou pressupor que você viu os tutoriais anteriores a esse. Meus tutoriais são ordenados de maneira lógica e sugiro fortemente que você se atenha à ordem deles para maior compreensão.
Conteúdo
- Não linearidade
- Contornando o problema com modelos lineares
- Regressão polinomial
- Considerações finais
- Referências
Não linearidade
Os modelos de regressão linear ou logística são ótimos para aprender fenômenos simples, nos quais as variáveis interagem de forma linear. Uma interação entre variáveis é linear quando a variação conjunta que acontece nelas é constante. Por exemplo, imagine que você consiga escrever artigos científicos num ritmo de 1 página por hora. Nós podemos colocar em um gráfico uma função que diga o número de páginas escritas dado o número de horas trabalhadas. Essa função será uma reta ou linha, daí o nome linear:
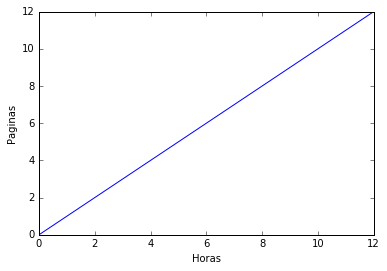
Como a relação entre horas trabalhadas e páginas escritas é linear, a variação conjunta que acontece entre elas é constante, ou seja, se você trabalhar uma hora a mais, também escreverá uma página a mais, independentemente da quantidade de horas que já trabalhou naquele dia. Como os modelos lineares ajustam uma reta aos dados (ou acham uma reta de separação, no caso de problemas de classificação), eles são suficientes para aprender esse tipo de relação nos dados.
Infelizmente, quase nenhuma relação que observamos no mundo é linear, principalmente as de interesse das ciências humanas. No nosso exemplo de páginas escritas por horas trabalhadas, por exemplo, é muito mais provável que em uma hora a mais de trabalho se produza menos do que na última hora trabalhada. Isso porque nós geralmente vamos nos cansando ao longo do tempo, o que diminui nossa produtividade. Nesse caso, o aumento de páginas escritas não aumenta de forma constante com um aumento de horas trabalhadas. Provavelmente, você seria bem mais produtivo nas primeira horas de trabalho e então sua produtividade cairia com as horas trabalhadas:
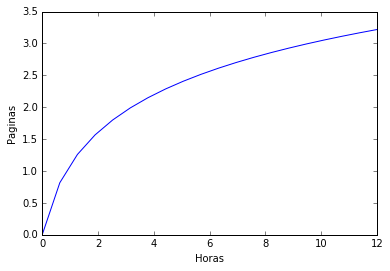
Assim, a função de páginas escritas por horas trabalhadas não seria mais uma reta, mas sim uma espécie de curva que cresce cada vez menos. Em economia, esse tipo de relação leva o nome de marginal decrescente. Por exemplo, podemos dizer que a produção de páginas é marginalmente decrescentes com a quantidade de horas trabalhadas. As relações marginais decrescentes são tão comuns nas interações humanas que uma grande parte da teoria econômica é dedicada ao estudo aprofundado delas. Apenas para citar alguns exemplos, podemos dizer que a produtividade é marginalmente decrescente com o capital investido, a saciação da fome é marginalmente decrescente com a quantidade de comida ingerida, a satisfação com um hobbie é marginalmente decrescente com o tempo despendido nele, a felicidade é marginalmente decrescente com o salário...
Sê você não consegue ver ainda como todas essas relações são marginalmente decrescentes, não se preocupe. Realmente leva tempo para se acostumar com esses termos técnicos. É preciso entender apenas dois fatos: (1) sempre que as coisas vão perdendo a graça conforme temos mais delas (em quantidade ou tempo), estamos diante de uma relação marginalmente decrescente; (2) fenômenos marginalmente decrescentes são extremamente comuns e não são lineares!
Assim, se quisermos utilizar nossas técnicas de Aprendizado de Máquina para entender melhor essas relações, precisaremos aprender as não linearidades de alguma forma.
Contornando o problema com modelos lineares
Até aqui, os modelos que criamos só foram utilizados para aprender relações lineares. Felizmente, é bastante simples modificá-los para que possamos aprender qualquer tipo de relação nos dados. Na verdade, sequer vamos modificar o algoritmo de treino em si; a única coisa que precisaremos fazer será forjar algumas variáveis novas a partir dos nossos dados.
Vamos voltar ao nosso exemplo de produtividade e dizer que a quantidade de páginas escritas (\( y \)) se relaciona da seguinte forma com as horas trabalhadas (\( x \)):
\[y= 3x - 0,1x^2 + \epsilon\]Como sempre, nós, como ignorantes cientistas, não sabemos essa relação, mas conseguimos coletar dados com horas trabalhadas e páginas escritas. Podemos então colocar esses dados em um gráfico e veremos que eles têm mais ou menos a seguinte forma:
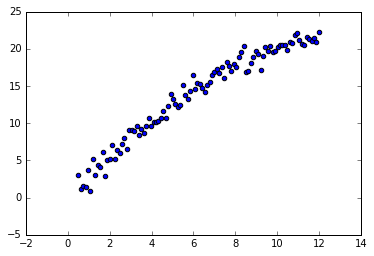
Embora não saibamos exatamente a relação entre páginas escritas e horas trabalhadas, podemos ter quase certeza de que nossa produtividade é marginalmente decrescente com as horas trabalhadas. Nós então decidimos utilizar um modelo de regressão linear para aprender essa relação. Mas para que seja possível aprender a não linearidade, é preciso que criemos novas variáveis que permitam uma representação não linear dos dados.
Nos nossos dados originais, só temos variáveis \( x \) e \( y \), mas podemos facilmente criar uma variável que seja \( x \) elevada ao quadrado. Assim, nossos dados incluirão uma nova variável: \( x^2 \). As primeiras 5 linhas ficariam assim:
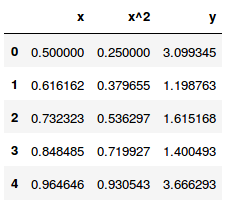
Nós então procedemos normalmente com a regressão linear múltipla de \( x \) e \( x^2 \) em \( y \) e aprendemos uma espécie de curva:
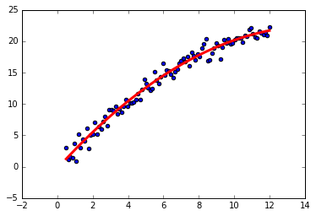
Podemos ver que a curva aprendida se assemelha bem ao processo gerador de dados. No entanto, para isso foi preciso que soubéssemos qual variável adicionar aos dados (nesse caso, \( x^2 \)). Essa forma de aprender não linearidades tem uma séria desvantagem, que é essa necessidade de saber qual a forma funcional do processo gerador de dados.
No exemplo acima, bastaria colocar os dados em um gráfico para saber que havia uma relação marginalmente decrescente. No entanto, na maioria das vezes não poderemos fazer isso, pois os dados terão mais dimensões do que caberão em um gráfico. Por exemplo, suponha que o número de páginas escritas não dependa mais apenas das horas de trabalho (\( x_1 \)), mas também da quantidade de sono na noite passada (\( x_2 \)) e do número de xícaras de café ingeridas na última hora (\( x_3 \)). Essa dependência pode ser bem complicada, como por exemplo \( y= (3x_1 - 0,1x_1^2) x_2 + 4 * \frac{x_3}{x_2} + \epsilon \). Se não soubermos exatamente a forma funcional dessas relações, isto é, se não soubermos que ela é da forma \( y= (Ax_1 - Bx_1^2) x_2 + C * \frac{x_3}{x_2} + \epsilon \), não teremos como ajustar o modelo aos dados.
Regressão polinomial
Mesmo sem saber a forma funcional do processo gerador de dados, podemos desenvolver uma técnica geral que funciona bem para problemas de relações não lineares. Em primeiro lugar, é preciso lembrar que, teoricamente, podemos aproximar qualquer função com um polinômio. Então, nós vamos utilizar esse fato para estender regressão linear para regressão polinomial. A ideia é bastante simples: a partir das variáveis existentes, nós vamos construindo novas variáveis polinomiais e a regressão com elas terá mais capacidade quanto maior o grau do polinômio criado. É importante ressaltar que o algoritmo de regressão linear não muda! A única coisa que muda é que agora forjamos várias variáveis polinomiais, por exemplo, elevando elas ao quadrado, ao cubo, à quarta, etc.
Vamos considerar um outro exemplo ilustrativo, no qual o crescimento do PIB brasileiro seja uma função sazonal do tempo, com picos e vales, mais uma tendência ascendente. Nós podemos simular dados dessa forma com a função seno. Particularmente, vamos supor que
\[PIB = sen\big(\frac{t}{1.5}\big) + 0.1t + \epsilon\]A função seno só pode ser aproximada com um polinômio de grau infinito, mas nós podemos produzir uma bom resultado nos dados acima com polinômios de menor grau. Particularmente, vamos ajustar 3 modelos aos dados, um com polinômio de grau 2, outro com polinômio de grau 4 e outro, com grau 11. Para criar as variáveis polinomiais, vamos utilizar uma função já pronta do Sklearn:
# Adaptado de
#http://scikit-learn.org/stable/auto_examples/linear_model/plot_polynomial_interpolation.html
from sklearn.preprocessing import PolynomialFeatures
from sklearn.pipeline import make_pipeline
from sklearn.linear_model import LinearRegression
import numpy as np
np.random.seed(3)
def f(x):
""" Função de crescimento do PIB"""
return np.sin(x/1.5) + x*.1 + np.random.normal(0,0.15,size=x.shape)
# Gera pontos
x_plot = np.linspace(0, 15, 100)
# Gera os dados e usa um subset para treino
x = np.linspace(0, 15, 100)
rng = np.random.RandomState(0)
rng.shuffle(x)
x_train = np.sort(x[:10])
x_test = np.sort(x[10:])
y = f(x_train)
y_test = f(x_test)
X = x_train[:, np.newaxis]
X_plot = x_plot[:, np.newaxis]
# parâmetros do gráfico
colors = ['teal', 'yellowgreen', 'orange']
lw = 2
# ajusta polinômios de graus 2, 4 e 10.
for count, degree in enumerate([2, 4, 11]):
# crias as variáveis polinomiais e as passa pelo modelo de regressão linear
model = make_pipeline(PolynomialFeatures(degree), LinearRegression())
model.fit(X, y)
# coloca as previsões no gráfico
y_plot = model.predict(X_plot)
plt.plot(x_plot, y_plot, color=colors[count], linewidth=lw,
label="Grau %d" % degree)
plt.scatter(x_train, y, color='navy', s=30, marker='o')
plt.ylim([-2,4])
plt.legend(loc='best')
plt.show()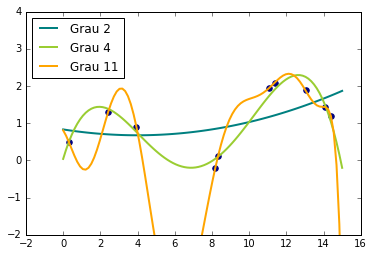
Note como a capacidade de ajustamento aos dados é mais forte conforme aumentamos o grau do polinômio. Isso traz à tona o tradeoff entre capacidade e generalização. No caso acima, por exemplo, o modelo com polinômio de grau 11 acerta todos os dados de treinamento, mas é provável que a variância dele seja muito alta, podendo comprometer a performance de generalização. Por outro lado, o modelo com polinômio de grau 2 não consegue sequer capturar as curvaturas dos dados de treino. Assim, podemos especular que esse modelo sofre com muito viés e está sub-ajustado. Por fim, o modelo com polinômio de grau 4 parece se ajustar bem aos dados, sem acertá-los perfeitamente. É provável que esse seja o nosso melhor modelo, em termos de erro de generalização.
No entanto, nós só podemos ter certeza vendo a performance dos modelos treinados acima em um set teste, isto é, que não foi utilizado para trainar os modelos. Apenas assim ficará claro que o modelo com grau 2 está sub-ajustando, o modelo com grau 11 está sobre-ajustando e o modelo com grau 4 parece ajustar bem.
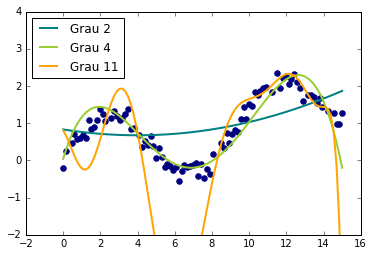
Considerações finais
Vale aqui ressaltar algumas desvantagens do modelo de regressão polinomial e deixar algumas recomendações para quando utilizá-lo e quando não. Uma grande limitação do modelo de regressão linear é que a máquina não aprende a forma da não linearidade, ficando essa parte sob responsabilidade da pessoa que está montando o modelo. Em outras palavras, é preciso codificar à força a não linearidade no algoritmo e isso é feito forjando variáveis novas. Por muito tempo, essa foi a principal forma de aprender não linearidades, mas hoje existem métodos muito mais eficientes para isso. A segunda desvantagem do modelo de regressão polinomial é que ele não funciona bem quando temos muitas variáveis e o grau do polinômio é muito alto. Isso porque o número de variáveis cresce exponencialmente com o grau do polinômio ajustado, tornando o aprendizado impraticável rapidamente.
Assim, é recomendável utilizar regressão polinomial apenas em casos de não linearidades mais simples, por exemplo quando se desconfia de alguma relação marginalmente decrescente (ou marginalmente crescente). Nesses casos, utilizar um polinômio de grau dois basta e polinômios com grau superior tendem a sobre-ajustar.
Referências
Como o algoritmo de regressão polinomial é essencialmente o mesmo de regressão linear, não colocarei nenhuma referência a mais. A implementação do tutorial acima está no meu GitHub.











