Posted on 12/09/2017
Neste tutorial não vamos implementar nada e nenhum código será utilizado. Vou apenas explicar o que são as Redes Neurais Recorrentes de uma maneira intuitiva e matemática. Há várias formas de utilizar RNRs, o que significa que nenhum exemplo pode ser geral o suficiente para abarcar todos os casos. Assim, prefiro primeiro cobrir os aspectos teóricos desse modelo e depois dedicar tutoriais de programação lidando com as diversas aplicações.
Pré-requisitos
Vou pressupor que você tenha os conhecimentos especificados no tutorial sobre matemática e programação para aprendizado de máquina, isto é, que sabe cálculo (derivadas), o básico de álgebra linear, de estatística e de programação. Eu também vou pressupor que você viu os tutoriais anteriores a esse. Meus tutoriais são ordenados de maneira lógica e sugiro fortemente que você se atenha à ordem deles para maior compreensão.
Conteúdo
Motivação
Eu aposto que você consegue recitar o alfabeto sem maiores problemas. Agora tente recitá-lo de trás para frente e você verá que esta última tarefa é bem mais difícil. Vamos tentar outro experimento. Tente ler a seguinte frase:
Miséria nossa de legado o criatura nenhuma a transmiti não, filhos tive não.
Ela não faz muito sentido, mas se a colocarmos na ordem certa você facilmente reconhecerá o fim de Memórias Póstumas de Brás Cubas:
Não tive filhos, não transmiti a nenhuma criatura o legado de nossa miséria.
Os dois experimentos acima mostram que algumas informações se fazem presente não apenas pelo conteúdo que as compõe, mas também pela maneira como esse conteúdo está disposto. Em termos mais simples, podemos dizer que existem informações que são sequenciais por natureza. Palavras, frases e enredos são os exemplos mais típico desse tipo de informação, mas não precisamos nos limitar a isso. Quando você vê uma cena em movimento seu cérebro antecipa o que vai acontecer, de forma que uma pausa ou um movimento revertido pode causar estranheza. De fato, estamos sempre prevendo o futuro, seja projetando a trajetória de um objeto que é jogado em sua direção, seja antecipando o sabor do almoço pelo aroma que vem da cozinha.
Dados sequenciais também são comuns em outros campos que não são tão relacionados com a percepção humana. Um exemplo são séries de tempo, como o preço de ações, a taxa de juros ou as exportações de um país. Outros exemplos são dados de transação bancária por cliente, características das escolas registradas anualmente no censo escolar ou compras por produto registradas em um supermercado diariamente.
A forma mais tradicional de lidar com esse tipo de dado é com variáveis defasadas. Por exemplo, se você tem dados diários de demanda de sorvete e temperatura, pode ser uma boa ideia usar essas duas vaiáveis defasadas 2 dias para tentar prever a demanda de sorvete no dia seguinte. Nesse caso a variável dependente seria \(y=demanda_{t+1}\) e as variáveis independentes seriam \(\pmb{x}=[demanda_{t}, demanda_{t-1}, temp_{t}, temp_{t-1}]\). No entanto, há alguns problemas com essa representação. Por exemplo, como fazer para decidir quantas defasagens é suficiente? Uma vez decidido isso, o que fazer quando algumas observações não têm nem sequer o número mínimo de defasagens? E o que fazer quando o tamanho das sequências é variável? Além disso, se cada observação no tempo tiver muitas variáveis, defasá-las gerará um vetor \(\pmb{x}\) tão grande que talvez não caiba na memória!
Não seria ótimo então um modelo que pudesse operar em sequências independentemente do seu tamanho e das suas variações? Melhor ainda seria se esse modelo não aumentasse de tamanho com o aumento das sequências. É para cumprir essas necessidades que podemos utilizar Redes Neurais Recorrentes. RNRs são Turing Completas, o que significa que seu poder é tão grande que elas têm a capacidade teórica de representar qualquer programa passível de ser feito em um computador. Esse tipo de modelo já existe há um bom tempo, mas só muito recentemente conseguimos alavancar seu enorme potencial para finalidades práticas.
Já aviso que esse é um dos modelos que mais tive dificuldade em entender, então não se assuste caso não o entenda de primeira. Se te parecer um conteúdo meio nebuloso, no final do post darei algumas dicas que podem lhe ajudar a aprender. Por enquanto, vem comigo!
Intuição
Considere uma rede neural com apenas uma camada oculta. Nesse caso, há apenas uma diferença fundamental entre as redes neurais recorrentes e as redes neurais clássicas que vimos até agora: a camada oculta das redes neurais feedforward totalmente conectada recebe sinais apenas da camada de entrada, isto é, dos dados brutos, processa esses sinais e os passa à camada de saída; a camada oculta da rede neural recorrente, por sua vez, recebe sinais tanto da camada de entrada quanto da camada oculta na iteração de tempo anterior. Em certo sentido, é como se a camada oculta da rede neural recorrente funcionasse como uma memória: a cada período no tempo, a rede neural não só armazena no seu estado oculto informações dos dados observados naquele período no tempo, como também recupera informações do estado oculto anterior que, num cenário ótimo, armazenou toda a informação relevante que aconteceu no passado. Mais ainda, o estado oculto nesse mesmo período de tempo pode fornecer informações para a camada de saída, caso seja o momento de realizar uma previsão, e também passa informações para o estado oculto do próximo período de tempo. De maneira mais resumida, o estado oculto da RNR recebe informações das variáveis independentes \( \pmb{X_t} \), assim como de seu próprio resultado de processamento \( \pmb{H}_{t-1} \), só que de um período de tempo atrás. Note que período de tempo aqui não representa o tempo do relógio, mas um tempo lógico que denota ordem numa sequência. Por exemplo, cada palavra em uma frase denota um período de tempo de processamento da RNR. Talvez seja melhor mostrar do que explicar:
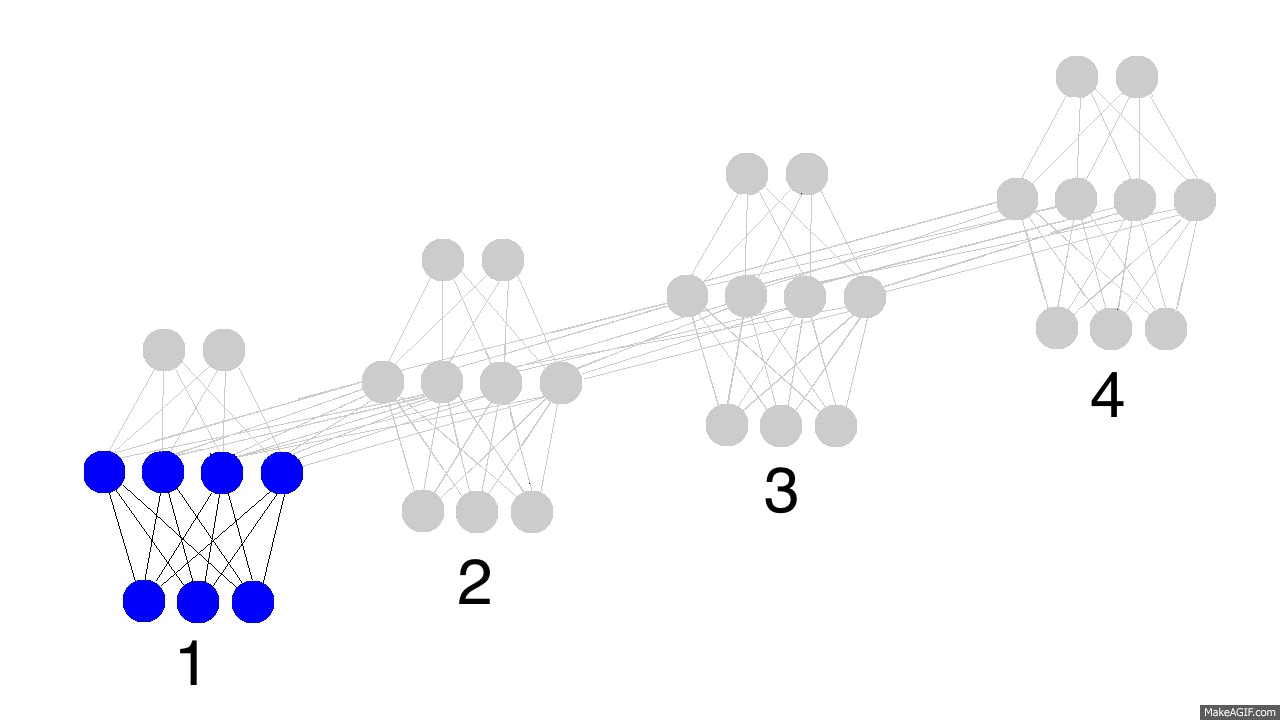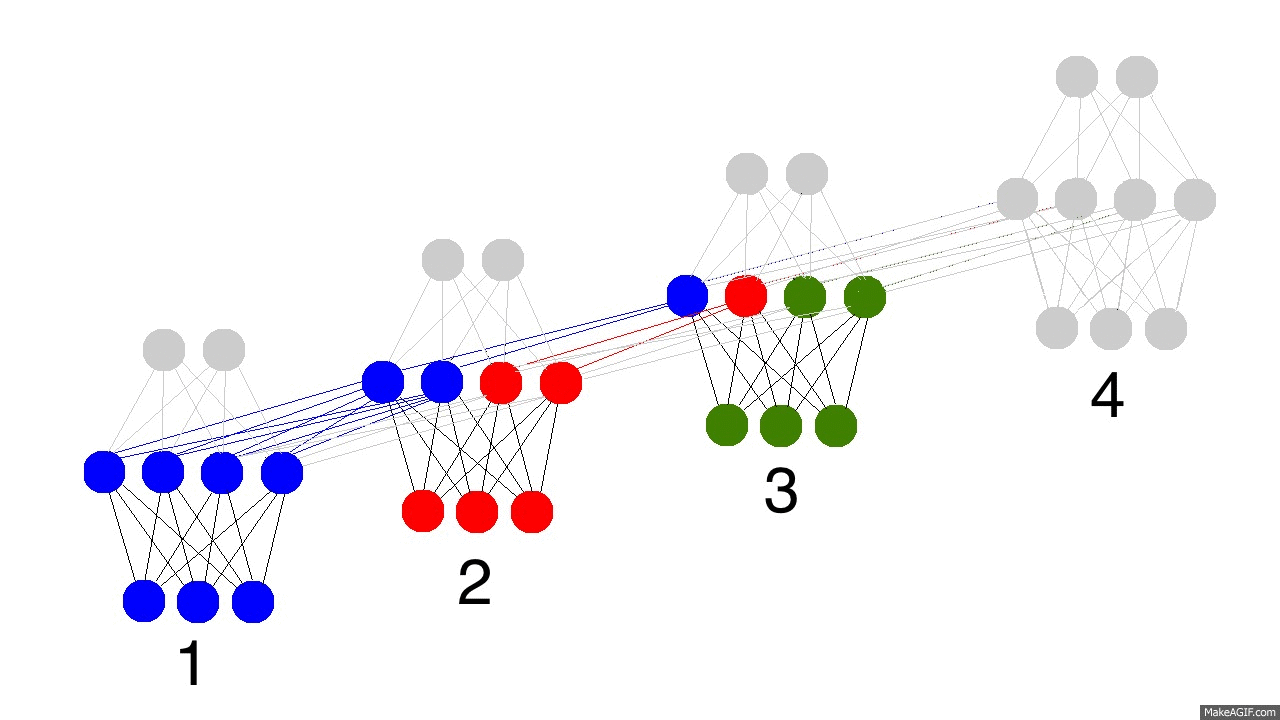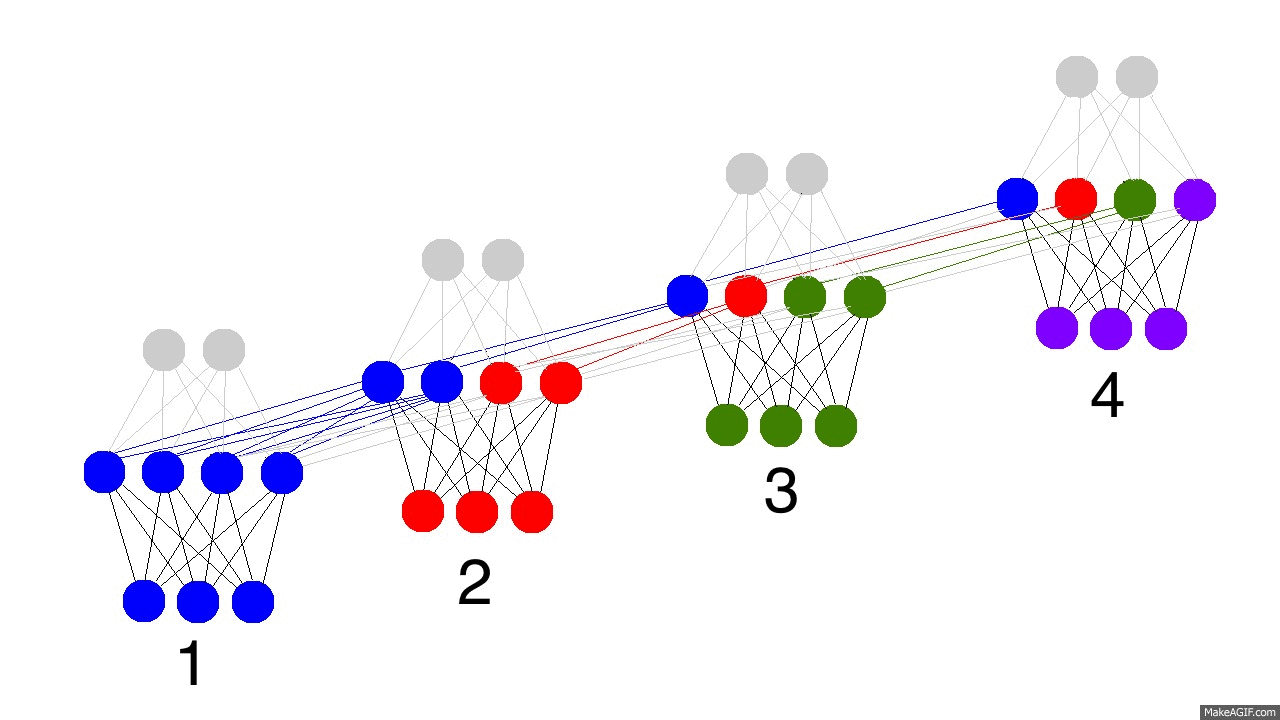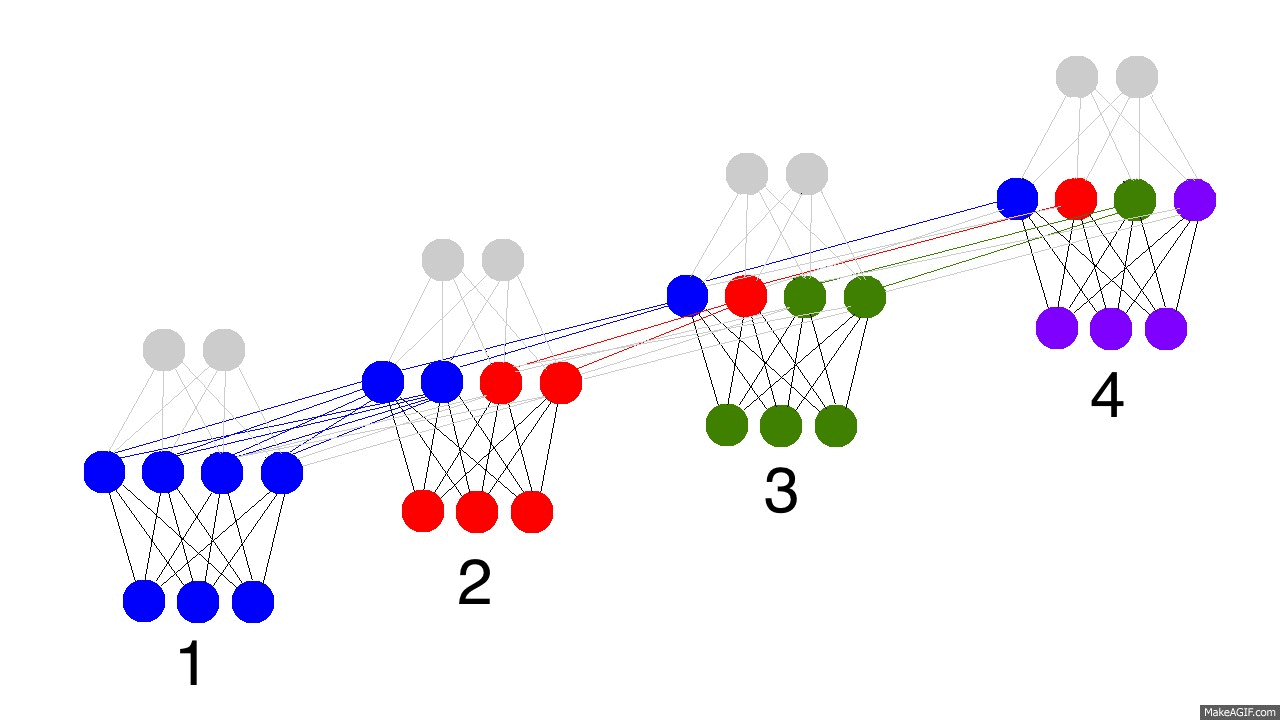
No GIF acima vemos o processamento que ocorre numa rede neural recorrente em quatro períodos de tempo. No primeiro, o estado oculto é puramente definido pelos dados, isto é, pela camada de entrada. Já o segundo estado, é uma mistura do primeiro estado oculto e dos dados observados no segundo período de tempo. O terceiro estado oculto contém uma mistura dos primeiro e segundo, além de conter informações dos dados observados no terceiro período de tempo. Finalmente, o quarto estado oculto contém um pouco da informação do que aconteceu em todos os períodos de tempo.
É importante notar que, na prática, a RNR escolhe o que armazenar e o que esquecer. Nos segundo e terceiro períodos de tempo, a RNR representada acima julgou que era importante usar metade do seu estado oculto para armazenar o que foi observado naqueles momentos. Já no quarto período, a RNR julgou que só um pouco da informação capturada valia a pena armazenar, utilizando apena um quarto do seu estado oculto para isso.
Aplicações
Você deve ter notado que o GIF acima não está mostrando informação saindo dos estados ocultos. Isso porque a forma como passamos a informação do estado oculto adiante pode variar drasticamente. Redes neurais recorrentes foram feitas para processar sequências, mas tanto a forma como essas sequências são lidas para a rede, quanto a forma como são geradas por ela, são ambas escolhas de arquitetura que dependerão do tipo de aplicação do modelo. Para entender melhor sobre isso, considere a imagem abaixo.
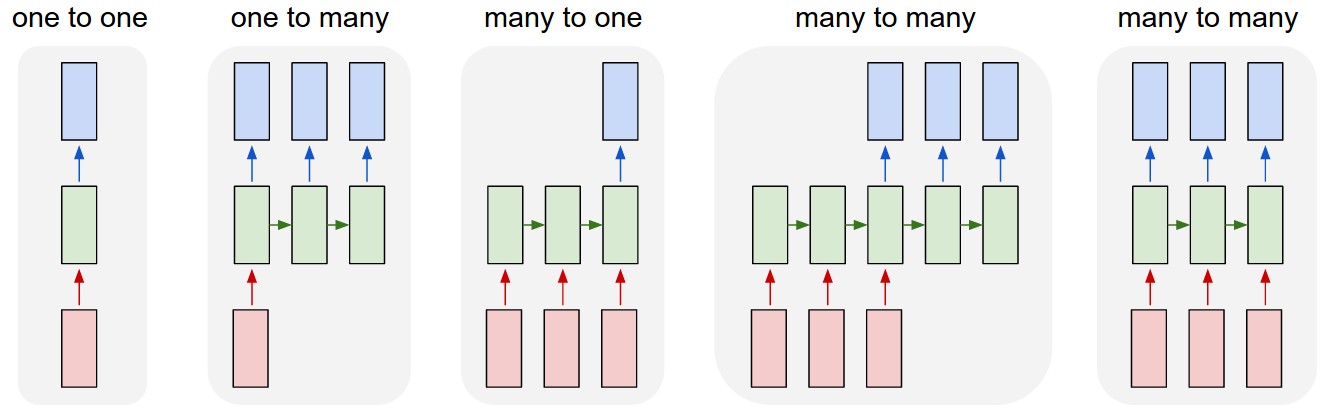
No caso one to one temos a clássica rede neural feedforward. Em aplicações one to many, lemos os dados uma única vez para o estado oculto e então passamos esse estado oculto adiante por vários períodos de tempo, nos quais também lemos informações contidas nele. Um exemplo de aplicação desse tipo é quando queremos criar um modelo para descrever imagens (image-captioning). Nesse caso, lemos a imagem uma vez para o estado oculto, mas lemos desse estado oculto várias vezes, uma vez para cada palavra gerada na descrição da imagem.
No caso many to one, lemos dos dados várias vezes, mas produzimos uma previsão apenas após ler toda a sequência. Um bom exemplo desse tipo de aplicação é classificação de texto, como analise de sentimentos, onde lemos o texto todo antes de realizar uma previsão.
Por fim, existem dois casos de aplicações many to many. Na primeira delas, nós lemos os dados por alguns períodos de tempo antes de começar a soltar previsões. Em outras palavras, há uma defasagem entre a leitura da sequência de entrada e a produção da sequência de saída. Um exemplo de aplicações desse tipo são casos de tradução por máquinas ou transcrição de áudio, onde a RNR lê a sequência por algum tempo antes de começar a gerar a sequência de saída, seja ela as palavras em outra língua ou as palavras correspondentes a um áudio. O último caso de many to many é quando temos sequências na entrada e na saída da rede, mas cada entrada corresponde a uma saída no mesmo período de tempo. Esse tipo de estrutura de dados aparece em séries de tempo e dados em painel, nas quais queremos realizar uma previsão para o período de tempo seguinte, dado o que ocorreu neste período de tempo e nos períodos anteriores.
Matemática
Se você prefere entender modelos com fórmulas em vez de explicações demoradas, aqui vão algumas equações que resumem tudo o que eu disse acima.
\[\pmb{h}_t = \phi(\pmb{b}_h + \pmb{x}\pmb{W}_x + \pmb{h}_{t-1}\pmb{W}_h)\] \[\pmb{\hat{y}}_t = \pmb{b}_o + \pmb{h}_t\pmb{W}_o\]Note que a diferença fundamental entre as equações acima e as das redes neurais clássicas é que adicionamos informação do estado oculto do período anterior: \(\pmb{h}_{t-1}\pmb{W}_h\). Mais ainda, Repare que os parâmetros que fazem a transição da informação entre os estados ocultos de diferentes períodos são sempre os mesmos. Isso mostra que redes neurais recorrentes compartilham parâmetros através do tempo. Na prática, definimos a recorrência acima como um loop no código, o que significa que, novamente, o modelo não passa de algumas multiplicações de matrizes, seguidas de funções de ativação. O que também significa que não há nenhum mistério na forma como ocorre a otimização por GDE. Em alguns lugares, você pode encontrar referências ao nome Backpropagation Through Time para treinar RNRs, mas isso nada mais é do que o algoritmo de Backpropagation que já vimos.
Se ainda não acredita, tente escrever as equações da RNR de forma desenrolada no tempo. Por exemplo, vamos considerar uma RNR com uma camada oculta, processando quatro períodos de tempo e realizando uma previsão de uma variável contínua (problema de regressão) apenas após observar os 4 períodos (caso many to one):
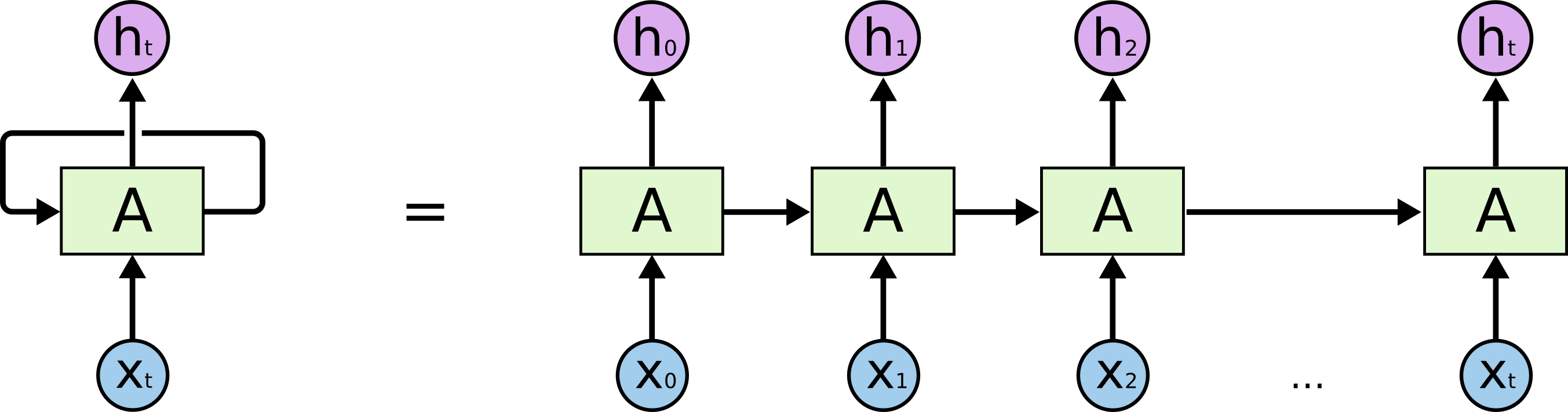
\[\pmb{H}_0 = \phi(\pmb{b}_h + \pmb{X}\pmb{W}_x)\] \[\pmb{H}_1 = \phi(\pmb{b}_h + \pmb{X}\pmb{W}_x + \pmb{H}_0\pmb{W}_h)\] \[\pmb{H}_2 = \phi(\pmb{b}_h + \pmb{X}\pmb{W}_x + \pmb{H}_1\pmb{W}_h)\] \[\pmb{H}_3 = \phi(\pmb{b}_h + \pmb{X}\pmb{W}_x + \pmb{H}_0\pmb{W}_h)\] \[\pmb{\hat{y}} = \pmb{b}_o + \pmb{H}_3\pmb{W}_o\] \[\mathcal{L} = \frac{1}{n} \sum_{i=0}^n (\hat{y} - y)^2\]O gradiente então pode ser calculado partindo da função custo, indo de trás para frente. Lembre-se de que não precisamos nos preocupar com isso, já que os frameworks de Deep Learning, como o TensorFlow, tomarão conta disso para nós computando as derivadas automaticamente. Também é importante notar que, muitas vezes, você verá RNR representadas como uma conexão recorrente, saindo do estado oculto e apontando de volta para ele, como esquerda da imagem abaixo. Essa representação é enganosa, pois dá a impressão que o estado oculto não muda. Assim, peço que você sempre pense em RNR como uma rede neural muito profunda, que se desenrola no tempo, como na direita da imagem abaixo.
Referêcnias
No momento em que escrevo, Redes Neurais Recorrentes são um dos tópicos mais efervescentes de Inteligência Artificial e Aprendizado de Máquina. Assim, é de se esperar que exista muito conteúdo explicando como elas funcionam. Caso você ainda tenha dúvidas depois de ler meu post, sugiro procurar informações sobre esse mesmo assunto em fontes diversas, assim poderá pegar de um autor o que outro deixou passar em sua explicação. Apenas tente evitar posts que misturem Redes Neurais Recorrentes com LSTM (Long Short-Term Memory). Essas útlimas são uma complicação a parte que ainda não vimos. Mas, caso esteja muito muito curioso, sugiro este post do Christopher Olah.
O melhor lugar para aprender sobre Redes Neurais Recorrentes é a aula 3, Language Modelling and RNRs Part 1, do curso Deep Learning for Natural Language Processing, da universidade de Oxford.
O segundo melhor lugar para aprender sobre RNRs são os vídeos de Geoffrey Hinton, para o Coursera. Assista os primeiros 4 desta playlist, mas não se preocupe ainda em entender LSTM.
Se você prefere aprender com livros, sugiro este capítulo do livro Deep Learning (Goodfellow et al, 2016).
Se você prefere aprender com blogs, este post, por Denny Britz, fornece uma apresentação bastante intuitiva e completa sobre RNRs. O post The Unreasonable Effectiveness of Recurrent Neural Networks, por Andrej Karpathy, é talvez o post mais famoso da internet sobre Redes Neurais Recorrentes. Eu recomendo muito que o leia para ver um pouco do enorme poder desse tipo de modelo.











